A.Amazon Sagemaker

SageMaker is a fully managed platform for building an ML and AI models and lot of customers interested in using the power of SageMaker to do model refining customization using fine tuning and reinforcement learning.
Customers, especially with AI agents, are interested in further improving on accuracy latency and cost optimization. So they are willing to invest in model customization starting from, you know, a bigger model and loading with their own data and information to make it task-specific, task-oriented.
A.1 Sagemaker AI serverless Model Customization
.png)
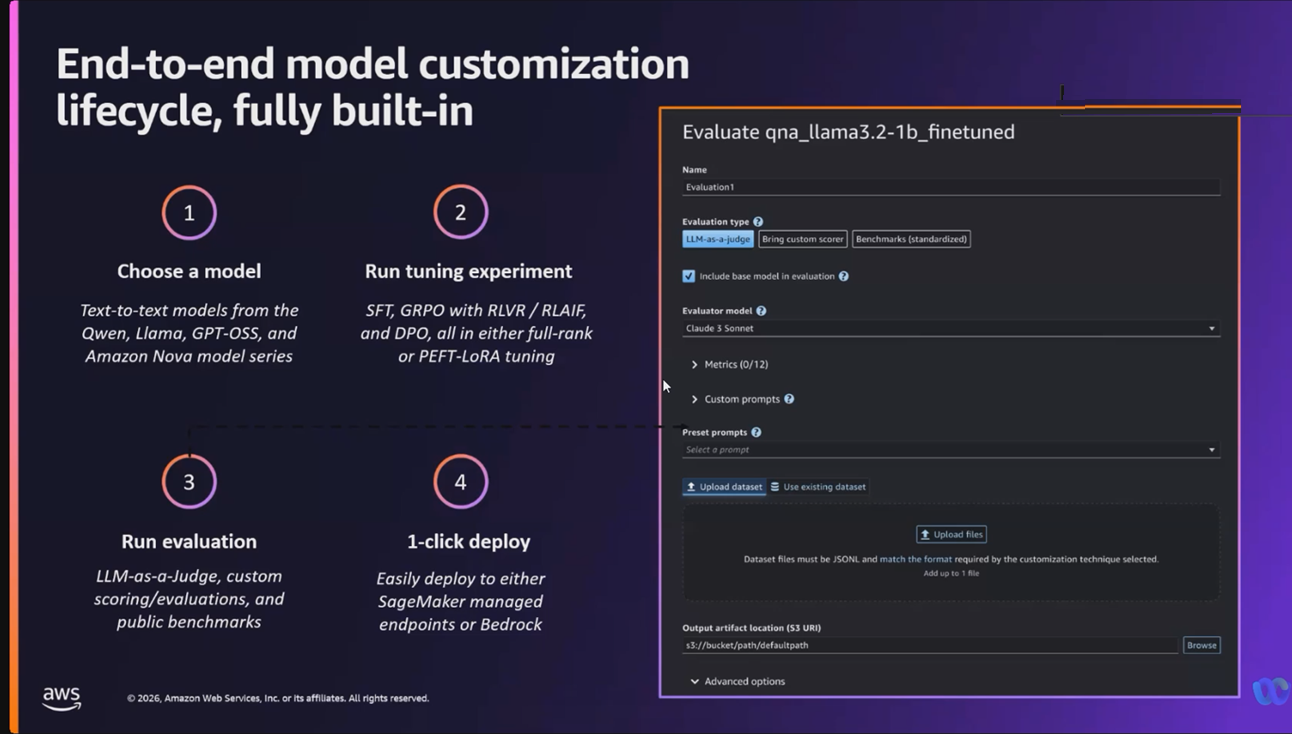
The new Sagemaker AI serverless Model Customization capability provides an easy-to-use interface for the latest fine-tuning techniques like reinforcement learning, so you can accelerate the AI model customization process from months to days.
With a few clicks, you can seamlessly select a model and customization technique, and handle model evaluation and deployment—all entirely serverless so you can focus on model tuning rather than managing infrastructure. When you choose serverless customization, SageMaker AI automatically selects and provisions the appropriate compute resources based on the model and data size.
Model customization made simple Comprehensive capabilities to customize models across the end-to-end workflow.
-
Data preparation (in preview): If real-world data is limited, you can easily generate synthetic data. If needed, the AI agent in SageMaker AI generates datasets based on data samples and contextual documents in the required format and structure for your selected model customization technique.
-
Advanced customization techniques: SageMaker AI supports the latest model customization techniques including supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning from AI feedback (RLAIF) and verifiable rewards (RLVR).
-
End-to-end serverless model customization: SageMaker AI automatically selects and provisions the appropriate compute resources based on the model and data size—all without requiring you to select and manage instances.
-
Inference: Once you have achieved your desired accuracy and performance goals, you can deploy models to production in a few clicks to either SageMaker AI inference endpoints or Amazon Bedrock for serverless inference.
-
LLMOps: You can automatically log all critical experiment metrics all without provisioning a tracking server or modifying code. Integration with MLflow also provides rich visualizations and an ingress into the MLflow user interface for further analysis.
A.2 Sagemaker AI Serverless MLflow
.png)
Amazon SageMaker AI with MLflow a serverless capability that dynamically manages infrastructure provisioning, scaling, and operations for artificial intelligence and machine learning (AI/ML) development tasks.
It scales resources up during intensive experimentation and down to zero when not in use, reducing operational overhead.
It introduces enterprise-scale features including seamless access management with cross-account sharing, automated version upgrades, and integration with SageMaker AI capabilities like model customization and pipelines.
A.3 Sagemaker HyperPod Checkpointless Training
.png)
Amazon SageMaker HyperPod now introduces checkpointless training, a foundational capability for large-scale foundation model training that eliminates the need for checkpoint-based, job-level restarts during fault recovery.
Instead of interrupting training workflows, this approach preserves forward training progress in the presence of failures, reducing recovery times from hours to minutes.
Traditional checkpoint-based recovery requires halting the entire training cluster, manually diagnosing failures, and restoring model state from persisted checkpoints—often leaving high-cost AI accelerators underutilized for extended periods.
Checkpointless training fundamentally changes this model by maintaining training state across the distributed cluster and enabling seamless, in-place recovery.
With checkpointless training, failed nodes are automatically replaced during runtime, and model state is recovered via peer-to-peer state transfer from healthy accelerators, without relying on external checkpoint restoration. By removing checkpoint dependencies from the recovery path, this approach significantly reduces idle accelerator time, lowers operational costs, and shortens overall training cycles. At scale, Amazon SageMaker HyperPod achieves over 95% training goodput on clusters comprising thousands of AI accelerators.
To get started, visit the Amazon SageMaker HyperPod product page and see the checkpointless training GitHub page for implementation guidance.
A.4 Elastic trainig for HyperPod

Elastic training is a new Amazon SageMaker HyperPod capability that automatically scales training jobs based on compute resource availability and workload priority.
Elastic training jobs can start with minimum compute resources required for model training and dynamically scale up or down through automatic checkpointing and resumption across different node configurations (world size).
Scaling is achieved by automatically adjusting the number of data-parallel replicas.
During high cluster utilization periods, elastic training jobs can be configured to automatically scale down in response to resource requests from higher-priority jobs, freeing up compute for critical workloads. When resources free up during off-peak periods, elastic training jobs automatically scale back up to accelerate training, then scale back down when higher-priority workloads need resources again.